What I Learned Building Bill
If, like me, you spend your weekends browsing technical documentation pages, you might have noticed that there’s something different on Plaid’s site. Specifically, you’d find that in addition to being able to search our site, there’s now a robot platypus there to answer all of your questions. Including, apparently, what Plaid products are most appropriate if you’ve been dumped by your girlfriend.
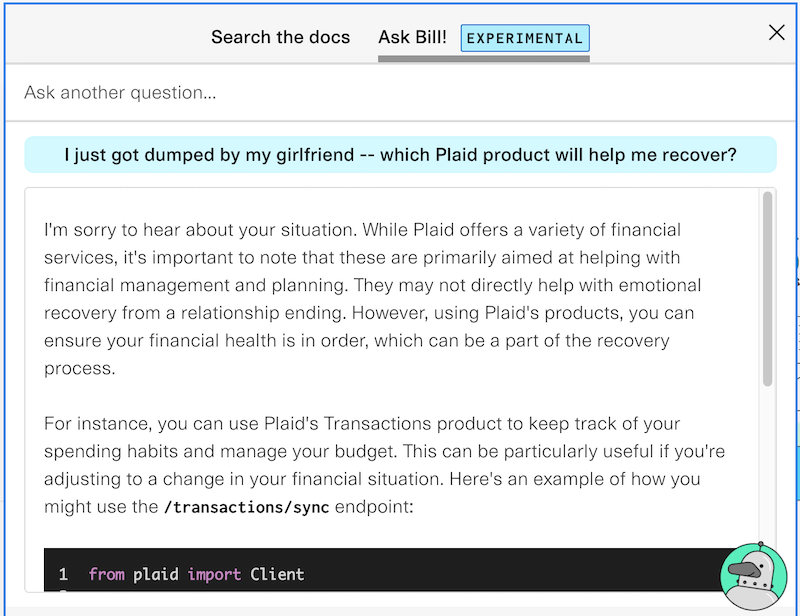
A co-worker sent this to me. I think he's going through some stuff.
In June of 2023, we turned on Bill (at the time known as “Finn”) to 100% of our customer base. And since then, it’s answered over 10,000 questions, helping developers jump-start their Plaid implementation, assisting them when they’re stuck, and shielding our support team from some unnecessary questions.
And it’s been met with a ton of great feedback; everything from “Whoa! This was genuinely useful!” to “Wait — we have a chatbot now?” * Note to self: We probably need to make discovery a bit better
So how did we build it, and what advice would I give for somebody else looking to add their own chatbot to the site? Well, I’ll get into that; but first, let’s start with a little history…
Table of contents
Open Table of contents
The Hackathon Project
Like many projects that fall under the “Fun little feature” category (I’m looking at you, Apple Watch Hand Washing Timer), Bill started off as a hackathon project. Plaid held its annual hackathon, known as Plaiderdays, in the spring of 2023 — right around the time that ChatGPT was in peak hype phase. GPT-4 had recently been released, and we all thought it would be great it we could build something on top of these nifty new AI-powered endpoints that they were giving us.
More importantly, a few people had already built their own custom chatbots and blogged about their process, so we didn’t have to start entirely from scratch. Frankly, that sounded like too much work.
After just a few days of hacking, we were able to put together a concept that worked pretty well. This is basically what it looked like, which I think is some pretty nice evidence that a) It was possible to create a useful chatbot for our docs, and b) Our team really needed a designer.
High level overview: How does it work?
I’m not going to go into all of the full implementation details, because there is a lot of existing content that covers this in tons of detail. But here’s a high-level overview of how chatbots like Bill work.
First, you take all the content you want to “train” the chatbot on. In our case, that’s our public documentation, the transcripts from our YouTube tutorials, a couple of implementation guides in .pdf form, and some content from our customer support team.
Then, you break all of that content up into a bunch of smaller chunks — typically, these are chunks that are, like, 3 paragraphs long. (Or roughly 400 words)
Then, and here’s where it gets a little tricky — you need to find a way to summarize the “general meaning” of that chunk of text. You do this by creating a vector that you can use to represent this piece of text in conceptual space.
For instance, let’s say I had a graph like this, where I differentiate between between fun activities and chores on the x-axis, and hot and cold things on the y-axis.
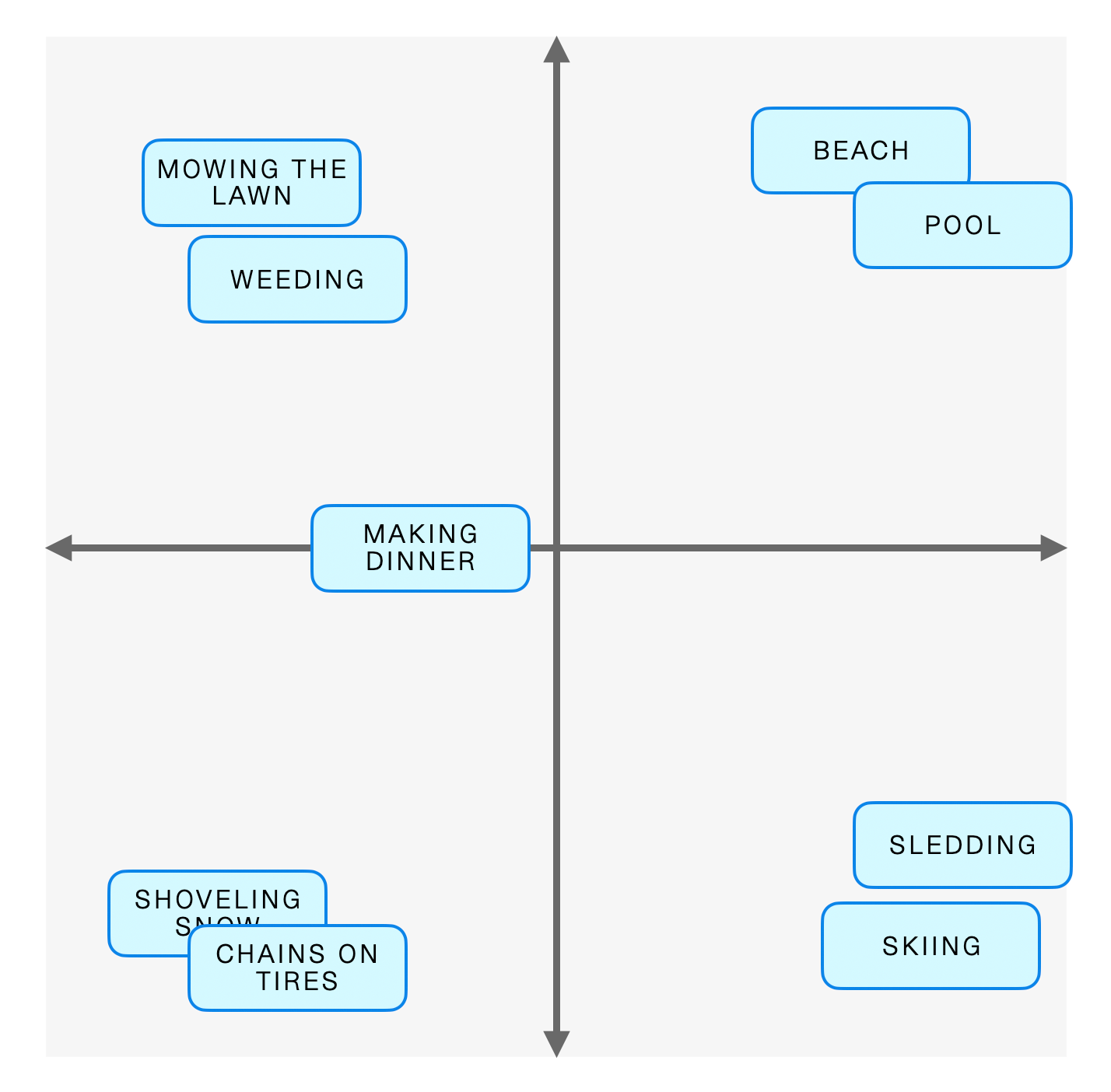
You can see that some things are fairly close together — cold-weather chores like shoveling the driveway and putting chains on your tires are pretty tightly clustered. And if I added another concept like “cross country skiing” to the graph, you’d probably have a good idea of where it would go. * Somewhere in the cold-weather activities, but more of a chore than downhill skiing, because who are we kidding here.
Now, imagine taking all of our content and putting it into a graph like this, except instead of a graph with 2 dimensions, you have a graph of over 1500 dimensions. That’s basically what we’re doing, but it’s hard to draw a 1536-dimensional space, so you’ll just have to imagine it.
And how do we actually do this? With an API call that OpenAI provides known as the embeddings API — you give it a piece of text, and it gives you the vector that best represents the overall “meaning” of this text. All of this data — the vector, as well as the original text — gets stored in a database. Specifically, we use a vector database that’s optimized for searching for vectors that are close to other vectors.
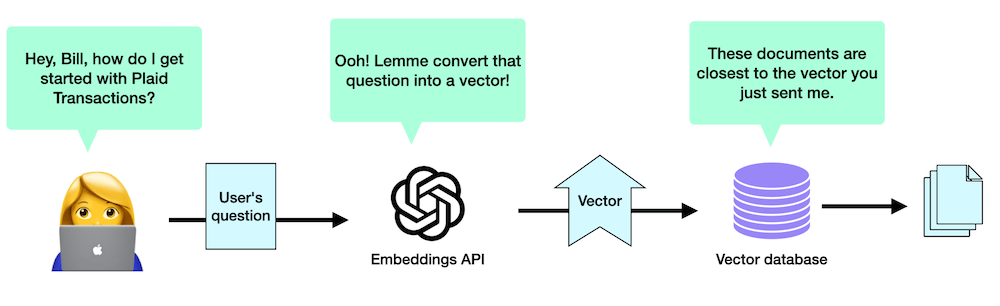
So, now, when a user asks a question, a few things happen under the hood.
- We pass that question along to the same AI algorithm that converted our original data into vectors (the embeddings API), and it creates a new vector based on the user’s question.
- Then, we ask our database to find a few vectors that are closest to the one that represents our user’s question, and send us back the original chunks of text associated with those vectors. This gives us several snippets of documentation that are likely to be relevant to the user’s question.
- Finally, we send the whole thing along to GPT. The final form of the question that we send to the AI is a simplified version of this:
You're a friendly chatbot looking to help developers with the Plaid API!
Your user has the following question
<question>
Here's some content that might be relevant to the user's question
<those chunks of text from our database>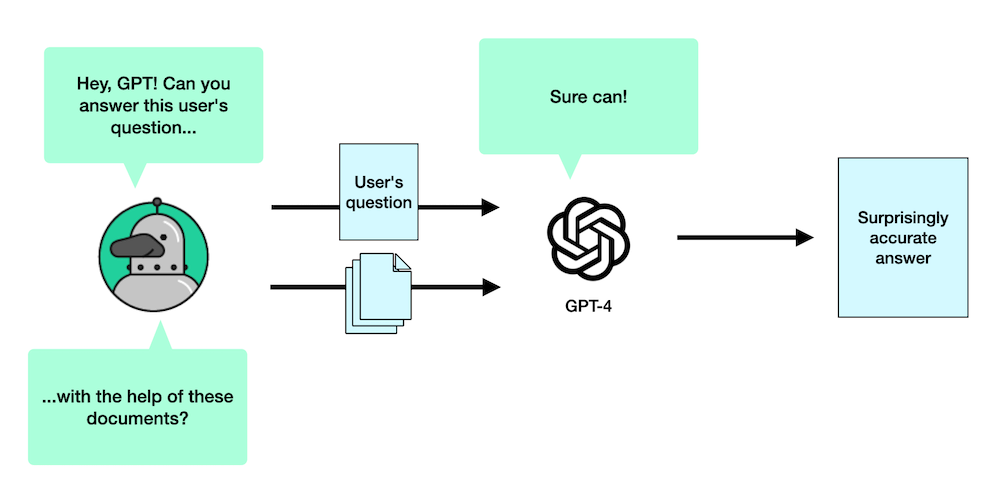
The thing to note here is that we never really “train” the model on our data. We just happen to give it the data it might need to answer the question. The analogy I like to use is that it’s the difference between studying for a test, and showing up for an open-book test with a magical notebook that automatically opens to the right page every time.
As an added bonus, if we keep track of the URLs originally associated with the chunks of text that we pass on to Bill, we can display those links to the user as a “For more information, check out these sites…” list.

These represent the URLs corresponding to the original content that we fed into our vector database
So that’s how our prototype works — and, as far as I can tell, this is basically how all “AI-powered chatbots trained on your documentation” work. We didn’t do anything particularly groundbreaking here, but it works really nicely, so why mess with success?
(Retroactively) Setting expectations
If you’re trying to decide whether or not to add your own chatbot to your site — either building it yourself, or using a third-party vendor — it probably helps to set up some expectations around what this chatbot will actually do for you.
I’d love to tell you these were our expectations going on, but in truth, we didn’t really know what it was capable of. It was more that after building it, we had a better idea of what our expectations should have been. So I’m going to just pretend I’m really wise and tell you these were our expectations from the beginning.
Will it replace my documentation?
First off, if you’re thinking, “This is great! Our customers won’t need to read anything — they’ll just tell the bot what kind of app they want to build and it’ll do all the work for them!” prepare to be disappointed. Bill is pretty smart, but he’s not at that level yet. Our customers are still better off reading our getting started guides first, and then asking Bill for clarification when they get stuck.
Along those lines, this will not replace the need for you to write good documentation. In fact, having a successful chatbot is highly dependent upon your having good documentation in the first place. But it will enhance your documentation in a few important ways:
- If you have information spread across several pages, a chatbot does a good job of bringing that disparate information together and presenting it all to your user in one convenient passage. Bill does great, for instance, when explaining the difference between two concepts that sound kinda similar.
- It can be a better search function than search. Search can work great when you know the name of the thing you’re supposed to search for, but often you don’t. Maybe you can only describe the question you’re having, and don’t know the term for the solution, or if it even exists. In those case, Bill does a really good job of knowing what information you’re searching for based on your question or problem.
- It really helps with rephrasing your generic documentation in a way that is very specific for the user’s use case.
That last point is really important. If you’ve ever written documentation before, you’ve probably described your product really well in terms of overall concepts; explaining in detail how something might work, and helping your users build a mental model of how things worked underneath the hood.
The problem is, developers don’t always want this. They want documentation that’s designed to solve their very specific problem. I know when I was at Firebase, we often got feedback that could be paraphrased as, “Your documentation is terrible because it just describes in thorough detail how storing and retrieving data works, and has nothing on how you would build a chat system kinda like Discord. Sincerely, a developer working on a chat system kinda like Discord.”
And, I know that sounds snarky, but this is valid feedback. Like, as somebody on your product team, you’re probably really invested in your product and think it’s in your customer’s best interest to understand how everything works underneath the hood so they can be as proficient as possible. But your customer just wants to know the minimum amount required so they can implement your feature and go back to romancing Shadowheart in Baldur’s Gate 3 * Or maybe Karlach. I'm undecided here. . And in that case, asking a chatbot to rephrase the documentation in a way that answers their specific question is a huge help. * I'm guilty of this, too. Langchain has lots of great conceptual documentation, that I totally skimmmed in favor of the use-case driven "Building a chatbot" section
Will it replace my support team?
Finally, for those of you who are thinking a chatbot is going to replace your support team, let me be clear that it won’t. But you can make their lives easier by not sending them questions they shouldn’t have received in the first place.
To oversimplify things a lot, if you look at a lot of the questions that your support team gets, a lot of them can be placed into two different categories
The developer has a question that could have been answered by digging around in the documentation a bit more.
The developer has an issue that requires digging around with internal tools and/or chatting with engineers inside the company. This includes questions like:
- “Hey, this person who’s our main account owner isn’t with the company anymore. Can you fix it!"
- "Can you explain why this call failed by digging through your internal logs?"
- "Can you enroll me with this beta feature?"
- "Something isn’t working as expected — is it a problem with the docs? Your code? Our code? The bank itself?”
Turns out, a docbot is really good at handling that first case, and not very good at the second. Meanwhile, your support team would rather spend their time focusing on those tough questions in the second category. So if you can prevent them from getting all those unnecessary questions from the first category, it’s a real win-win.
Build vs Buy
Once we decided that our prototype was good enough to turn into a real feature, the next big decision to tackle was whether we should continue taking what we had and turning it into something production-ready, or whether we scrap it all for an off-the-shelf solution.
There are some pretty good products out there that will create custom chatbots for you. You give them a list of URLs you want them to crawl, and they give you an API and/or embeddable widget that you can use on your site. I strongly suspect all of these products were following the same strategy we were using for Bill. As a result, the quality of answers for these off the shelf solutions was about the same level as what I was able to put together.
Depending on your perspective, you can walk away from this discovery with one of two takeaways:
- Why spend time building something, when I could pay for a solution that’s almost as good in quality?
- Why spend money buying something, when I could build something internally that’s about as good in quality?
And so, yeah, we had a lot of the same back-and-forth discussions that I suspect most teams have when making a build-vs-buy decision (up front cost vs. long term cost, time to market, vendor lock-in, maintenance burdens, customization, etc.). In the end, though, we decided to go ahead with building our own internal version, and that was for a few reasons:
- A lot of these products are just getting started and there were still a few bugs and missing features. While most of these companies were quite responsive to our feedback (and a bunch of issues have been fixed since our earlier evaluations), there was no guarantee they would prioritize anything that we might consider a blocker.
- I’m enough of an engineer that some part of me rebelled against the idea of paying for something that I could build myself.
- Plaid has a pretty strong culture of personal growth. Heck, it’s one of our main principles. And I’m reasonably sure that this AI thing is going to stick around for a while. So what better way to learn more about AI than by build a working product that actually uses it?
And that last point isn’t just a theoretical one — I’ve already been pulled into several meetings with other teams at Plaid who are interested in building their own AI-based tools and I’ve been able to share everything we’ve learned so far with them. And while I’ll admit that “Getting pulled into more meetings” was not one of my goals for 2023, it’s nice to feel wanted.
Of course, the flip side to this should be obvious to any developer who has claimed they could build Twitter in a weekend…
It turns out the work required to take a functional prototype and turn it into a production-ready feature is a lot more work than to get the initial prototype working. You have to worry about things like logging, support, scaling, monitoring, rate limiting, halfway-decent CSS, and all the boring-but-necessary features that make this a true product. * Honestly, one of the most difficult parts of moving to production was setting up a Python server that could stream data to browsers. That wasn't really something we were set up for.
Also, these commercial products have dedicated engineering teams working full-time to make their doc bots better and smarter and more powerful. We currently have… me, when I’m not making videos or writing overly-long blog posts. So I suspect that at some point in the future (let’s say more than 9 months, but less than two years), we’ll be swapping out our home grown version for a more mature commercial version.
So what I’d say is that if you don’t have the time, resources, or interest to learn any of this on your own, these third party solutions are a quick and easy way to get started adding a chatbot to your site. On the other hand, there’s something to be said for learning by doing, and a custom-made chatbot is a great introduction to the world of AI and LLMs.
To LangChain or Not?
When I first got started building Bill, I naturally assumed that I should build everything using LangChain. LangChain, if you’re not familiar, is a popular open source library that makes it incredibly easy to communicate with LLMs like GPT, query vector databases like Pinecone, and do a lot of the “scraping and chunking of data” that we need in order to populate our database. It’s what every tutorial out there seems to use, so I just assumed that’s what I would use to build our chatbot.
So it surprised me when I asked around the company and found that there were a few engineers here who decided not to use LangChain and just talk to the OpenAI endpoints directly. I kinda get why they did this — OpenAI’s endpoints are pretty easy to talk to. But also, there are a few challenges with LangChain that weren’t really obvious until I started using it in earnest.
First, the Python and the Node versions of the library are quite different — not just in terms of their implementation but their feature set. My initial prototype was built in Node, but I ended up switching to Python after I realized that the LangChain Python library had so many additional features.
Second, I think what I’ve found is that while LangChain is great at abstracting very complex chains of action into a single call, if you want to modify the behavior of those calls in any way, it can be quite difficult.
- As one example, I wanted Bill to return its sources — the urls associated with the embeddings — before it generated the rest of the answer. That wasn’t possible with the library’s built-in “Answer a question with a data source” method.
I ended up not using most of LangChain’s more sophisticated features. Instead, I kept to the more simple “Make a single call to the LLM” methods and then chained these calls together myself.
Third, hey, it’s a library that’s still very much in its infancy, so there were occasionally bugs, API inconsistencies, and other rough edges. And as a 0.x library, it doesn’t have to adhere to semantic versioning, so sometimes I’d upgrade to fix a bug, and something else would break because the method signature was different.
In spite of all of that, however, I am happy that I used LangChain — it greatly simplified the process for setting up our vector database, and my friends at Shortwave have been able to pull off some pretty sophisticated workflows using it. And, more importantly, it’s an open source library with dozens of smart contributors, so it’s only going to get better in the future. My point is more that there’s so many tutorials out there using LangChain, you might feel obligated to use it, and I’m here to say that if you want to do your own thing, that’s fine, too.
GPT-4 vs GPT-3.5-turbo
And other technology considerations
Probably most of you know the difference between these two models. GPT-3.5 is very fast and cheap, but not as smart, and prone to more hallucinations. GPT-4 is significantly more accurate, with the tradeoff of being slower and a lot more expensive — 20 to 30 times more expensive.
I think GPT-4’s reputation for being expensive has scared off quite a few people from even considering it. But for Bill, we ended up using GPT-4 because we felt like the higher accuracy was worth it. People were asking Bill some tricky edge-case-y questions, and GPT-3.5 would often get those trickier questions wrong.
Also, Plaid is in a situation where the economics make sense. We’re not a technology like React with millions of developers who are using it for free. We have several thousand customers, nearly all of whom are (or will be) paying for the service. For this audience, it’s worth our spending a few more dollars on OpenAI calls to help these customers be more successful implementing Plaid.
In practice, the costs for our OpenAI calls ended up pretty moderate, even using GPT-4. I’d say it’s roughly the equivalent to what I eat in free food at the office. So, in theory, I could probably compensate for Bill’s costs just by eating less dried mango. I mean, I won’t; but it’s nice to know I could, I guess.
Conversation Mode!
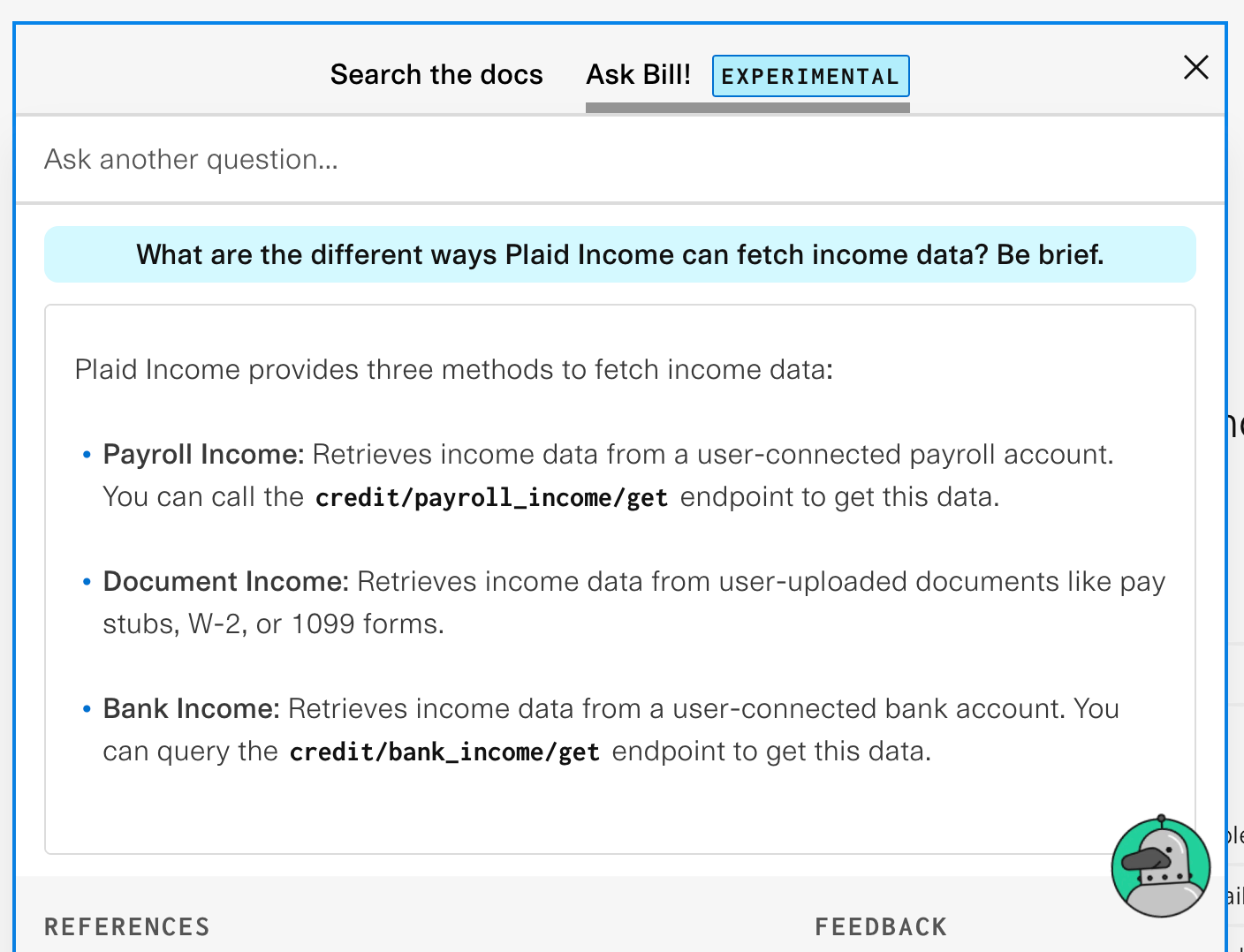
One of my favorite features of Bill is the fact that you can ask him follow-up questions. For example. I can start by asking him this…
…and then follow up with this…
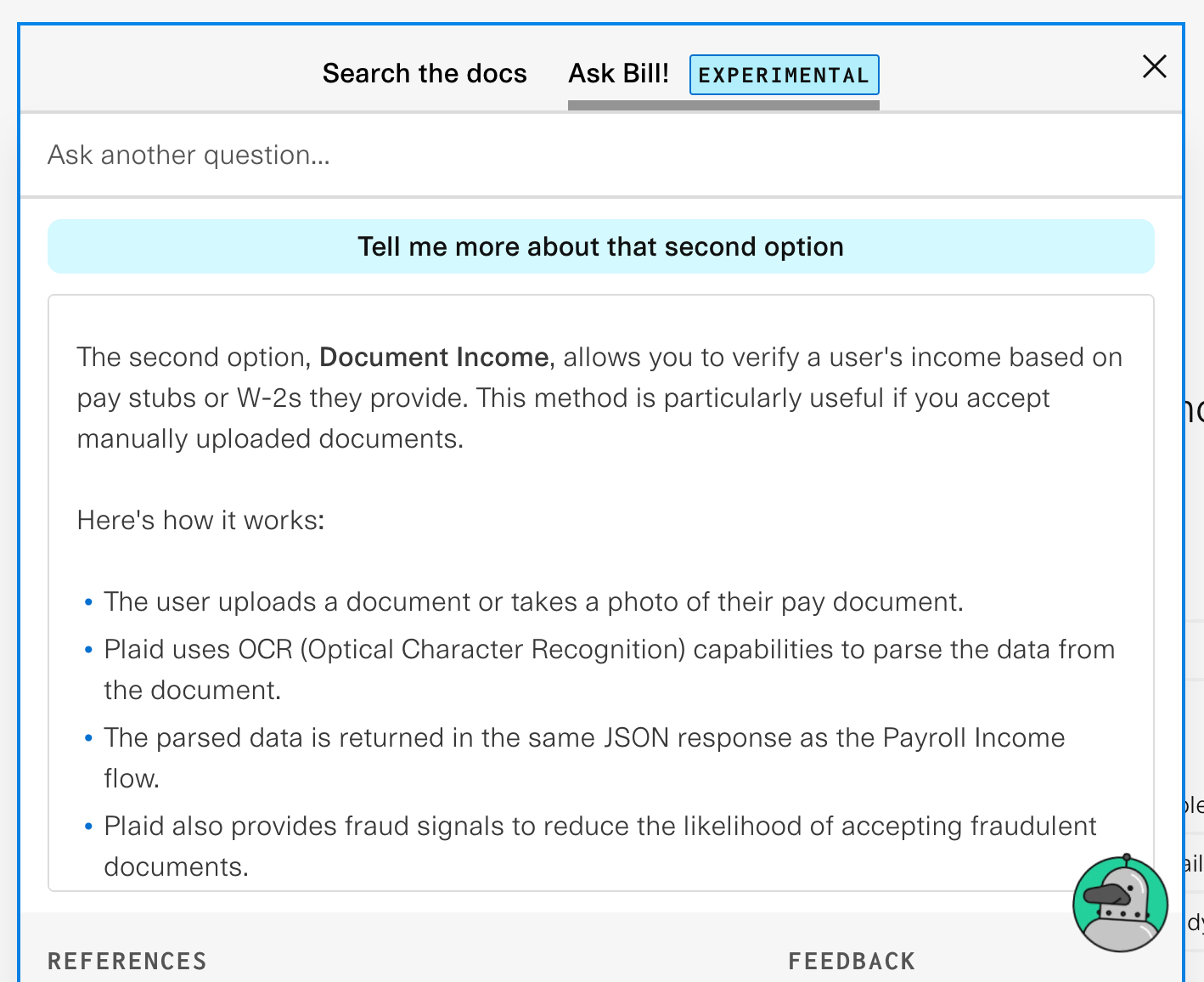
And Bill clearly understood, based our earlier conversation, what “that second option” meant. So, how does it know this?
The way this generally works in a lot of models is that, every time a user sends across a question, the browser will also send across the most recent list of questions and answers between the user and the chatbot. You then send this conversation history to GPT and say, “Hey, based on his chat history, can you rephrase our user’s most recent question to be a standalone question?” For example, in the previous exchange, GPT rephrased my question as
"What does the second option, Document Income, involve in terms of retrieving income data?"It’s pretty strangely worded, but it gets the point across. Once you have a standalone question, you can then just use your standalone question in lieu of the user’s original question moving forward. You’d use it to fetch the appropriate data from your database as well as send it off to your AI model for the final answer.
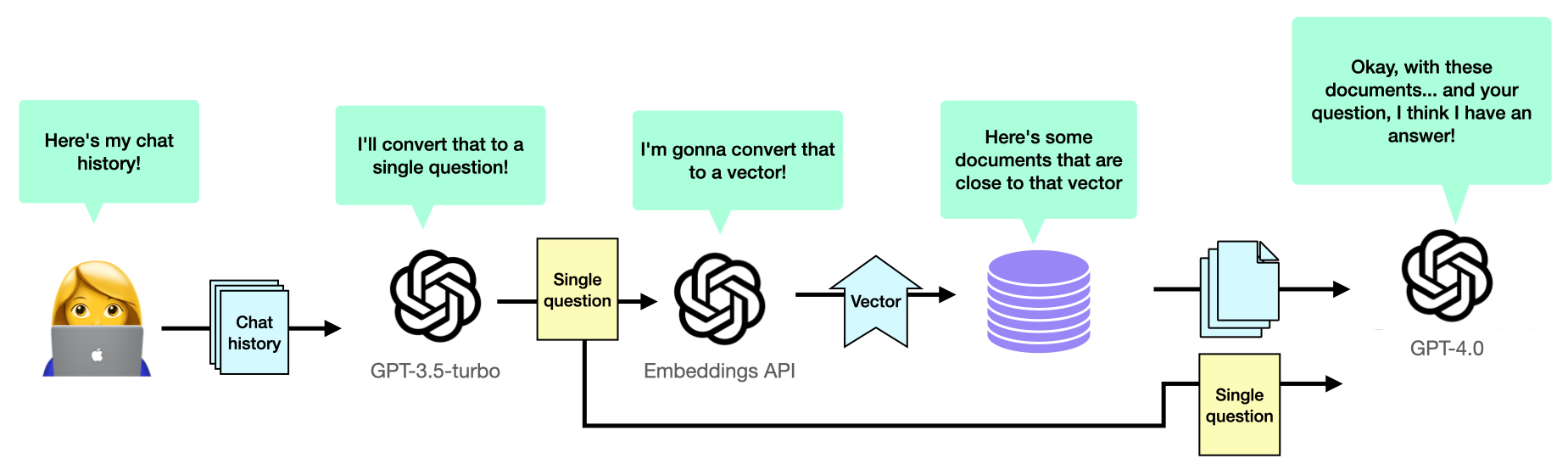
This worked okay, but I found that sometimes GPT would mangle the user’s original question pretty badly. This happened most often when our user tried to change the subject and ask an entirely different question. GPT would anchor the new question too heavily to the series of conversations that came before it.
I suspect part of this is I was using the “faster but not as smart” GPT-3.5-turbo model to perform this step — but I think that’s necessary here. Remember that this entire question needs to be resolved so you can retrieve the database docs and send all of that information back to chat GPT before the user sees a single word from your answer. And waiting for GPT-4 to parse that initial question here would be an unacceptable delay.
So my strategy to deal with this was the following: I would still go ahead and ask GPT-3.5 to create the standalone question, and then use that question to fetch embeddings. But when it came time to ask GPT-4 for the final answer, I would ignore the standalone question and send over the original chat history.
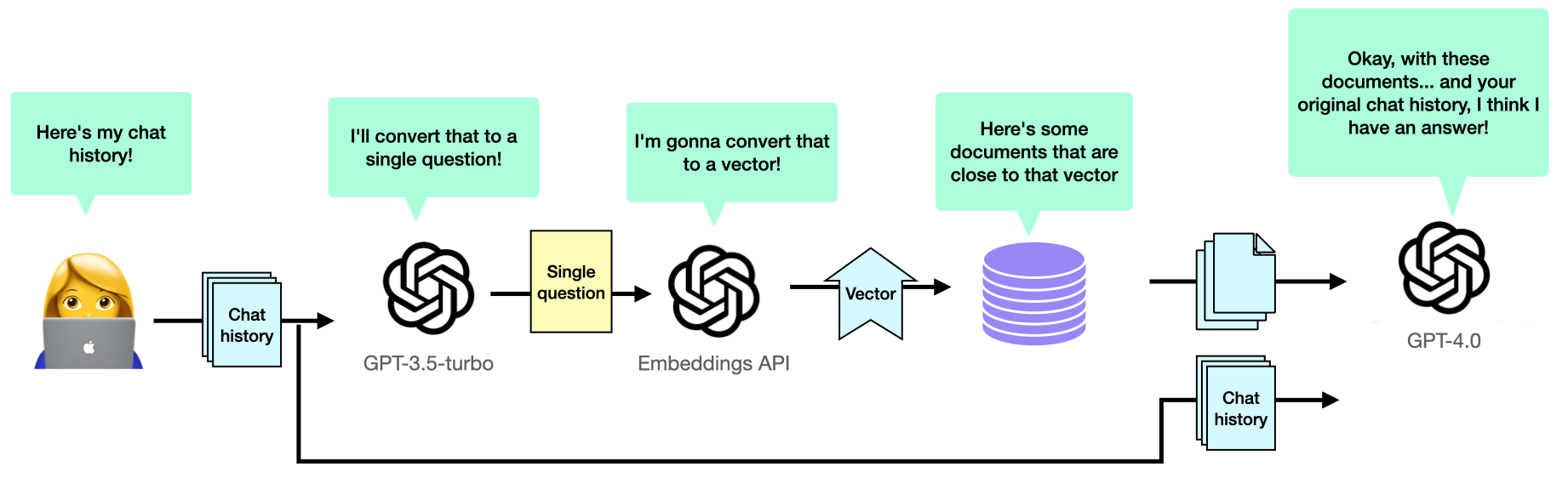
This meant that when it came time to answer the user’s question, we had the highest chance of understanding what the user originally meant, even if occasionally the embeddings were a little off.
More isn’t always better
We originally populated our database with all the content we possibly could — all of our documentation, all of our blog posts, all of our github pages and sample code. But it turns out maybe this wasn’t the right move. The issue we found is that if you have a lot of pages with a lot of similar content, they’ll end up dominating the embeddings that you give your chatbot, and this can “push out” other content that might be useful.
Plaid’s documentation in particular has a lot of “Implementing Auth with a specific partner” docs — take a look at this one and this one. There’s, like, over 30 pages like this where all the content is the same, except for that initial paragraph. If a user asks a question about Auth, we don’t want to send Bill four nearly identical pages — we probably want to grab some other, less redundant, content from our other docs pages. So we dropped most of these redundant pages from our database.
For blog posts and video tutorials you have to be careful because, unlike documentation pages, these tend to be frozen in time. People don’t go back and update old blog posts that often, and it’s nearly impossible to update old videos on YouTube. So, if you’re not careful, you could end up feeding your chatbot incorrect or outdated information.
We ended up not including too much marketing material either. The issue for a docs-powered chatbot is that this content often ends up being highly relevant (because it’s talking about the product that a user is asking about) but doesn’t contain the kind of implementation details a developer would be searching for, so, again, it runs the risk of pushing out other content that might be more useful.
With our sample source code, I was surprised to see how little of that content got sent to Bill. I think the issue came down to the vectors that were created to represent this code. We might have code that very specifically shows you how to, say, create a User Token in Python, but unless there’s some heavily commented code specifically stating that’s what this code does, the embedding model might embed this with more of a “Here is a bunch of Python code” vector.
We also experimented with changing the number of embeddings that we sent to Bill with each question. We started with 3, found that increasing the list to 4 gave us slightly better results, but then increasing the list any more than that sometimes gave us worse results. I suspect this is because Bill feels obligated to incorporate all the data you give it, even if it’s not as good.
Also, these documents tend to be pretty large chunks of text, which can drive up your OpenAI API costs, and if I was a fan of paying more money for a worse experience, I’d be drinking decaf coffee.
”But wait,” you’re saying to yourself. “How would you even know if you get better responses?” Glad you asked!
Evaluating Bill’s performance, part 1
One of the trickiest parts with developing Bill is that there’s a lot of tweaks and adjustments you can make to the model and you have no easy way to measure whether you’ve made things better or worse. I mean, it’s not like website performance where you have some objective easily-measurable stats that you can stick into an analytics package. You’re basically stuck comparing one plausible-sounding answer against another plausible-sounding answer.
So, how can you figure out if Bill’s answers are any good? You can ask Bill! We followed the strategy of my naive middle school teacher by asking GPT to grade its own homework. Luckily, unlike your typical 7th grader, GPT is quite honest and does a good job at evaluating itself.
So here’s what we did — we came up with a series of questions, followed by some bullet points around what the ideal answer would contain.

With the help of a few Python scripts, we sent those questions off to Bill, using the same embedding database and process that it uses to answer typical user questions on the website.
Once we get back those answers, we can send them along with the “ideal talking points” to GPT, and ask it to evaluate Bill’s answer based on these talking points. We then ask it to grade the answer on a scale of 0 to 100.

Our script then averages those scores out over each of these questions, and we end up with a number that’s a good general guideline around how good Bill’s answers tend to be.
Now, this score needs to be taken with a grain of salt. We’ve noticed a few occasions where Bill gave himself the same score for two answers, even though one was noticeably better than the other. But I think if you look at it in terms of broad strokes, this was a good sanity check to have when doing things like changing Bill’s prompt text, where small changes can have large, unforeseen impacts.
Evaluating Bill’s performance, part 2
In the end, though, evaluating Bill’s performance came down to having a human look over a sampling of questions and answers that Bill gave over time and simply just deciding if they were good or not. This was, frankly, a pretty difficult task, because Bill would give lots of answers that sounded really good, and it would take somebody with deep product knowledge to know if they were correct or not.
Luckily, my manager is one of those people, and she spent a lot of time evaluating the answers that Bill gave our users * At first, she was looking at every single answer question and answer, but now that Bill's grown more popular, it's really more of a spot-check Based on her evaluation, Bill is correct 70% of the time, “Mostly correct” 25% of the time, and “Wrong” 5% of the time.
While that’s fine for now, ideally I’d want to spread the work around a little by having Bill analyze a sample of the questions and answers it’s generated, decide what product team would be most likely to know the answer for sure, and then send it off to the appropriate Slack channel for validation. That’s also on my “Something to tackle one day” list.
What this means, though, is that running experiments with Bill is tough — there’s no simple way of running an A/B test and watching to see if some number goes up. You have to make a change and just kinda see if, over time, it “feels” like your chatbot has gotten better.
Why not rely on user feedback?
We have feedback buttons on our website, where users can decide if an answer is good or not. So why not rely on those? For a few reasons:
Nobody ever clicks these
- Nobody clicks those things. Maybe 1% of answers send feedback. I suppose we could be more aggressive around making people click those buttons, but I haven’t, because…
- These responses aren’t that reliable. Often times when Bill got a bad rating, it was because the user’s original question was bad. Or the user received a response that was perfectly accurate, but one they didn’t want to hear.
- Similarly, when Bill got a good rating, it was sometimes because he gave a great answer. But sometimes it was because he gave an answer that sounded good at the time but actually wasn’t.
What happens when Bill gets it wrong?
So, what do we do when Bill gets an answer wrong? How do we fix it?
Honestly, the first step towards fixing an answer is to figure out if Bill should have been able to get the correct answer from our docs. Often times, we realized Bill was wrong because certain things were missing from our documentation, or simply implied in places where it could have been made explicit. And that’s been one of the unexpected benefits of Bill; just seeing what people are asking him can help you figure out if there’s incomplete sections of your documentation.
Other times, though, this was a mystery. We’d see the right information in our documentation, but Bill wasn’t able to answer the user’s question correctly. Often this was because those portions of the documentation weren’t included as part of the context passed in to Bill. For instance, Bill had a very difficult time answering the question “Does Plaid provide APRs?” even though there’s a very significant chunk of our reference documentation dedicated to this. And that’s because this documentation, even though it exists in our database, wasn’t selected as one of the documents that got passed along to Bill
It’s tough to figure why this happened — the method of converting a chunk of text of a dimensional vector is a bit of a black box unless you’re really good at visualizing 1500 dimensional space. But I suspect the reason comes down to the fact that it’s possible for a chunk of text to contain multiple meanings — that chunk of reference documentation has information about APRs, but it also has information about overdue payments! And payment due dates! And mortgages!
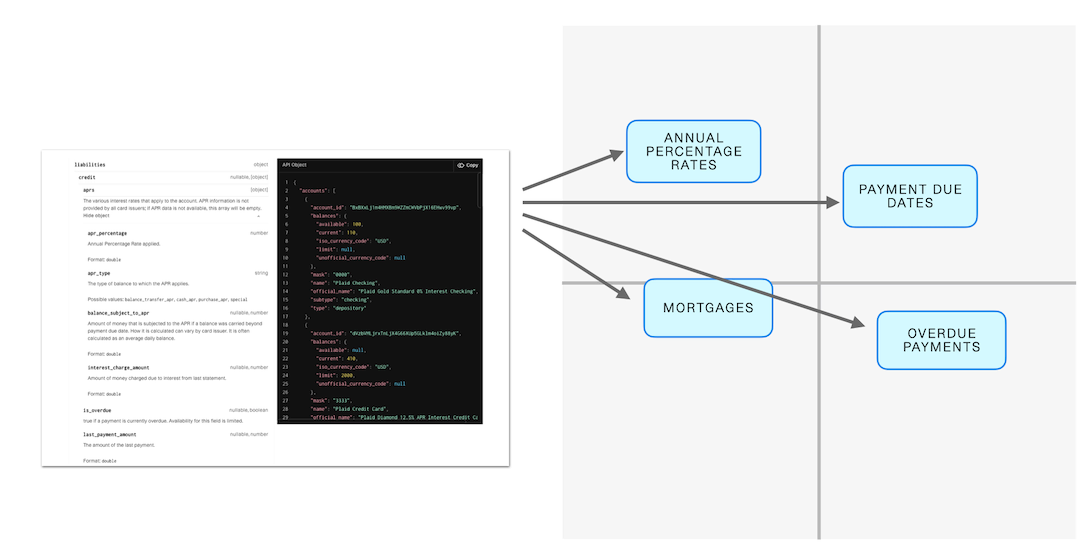
What you think happens when you parse text with multiple meanings
But our API needs to pick a single vector to represent that text. So I’m guessing it’s picking something that’s probably more along the lines of “Reference documentation for the Liabilities endpoint” than it is to anything related to “APRs”, which means our database won’t select it as one of the “4 closest documents”

Probably what actually happens
One way to address this might be to parse our reference documentation differently — I suspect there are ways we could be printing out our reference docs to be more “robot-friendly”, but also I want to look at splitting up our reference documentation into smaller chunks. Both of these options might improve our bot’s understanding of our reference docs.
But I suspect it’ll never be perfect, and when you have situations where your bot still can’t seem to figure out the right answer, we found that the best approach was to create an individual FAQ file that consists of the question and the ideal answer. These then get fed into Bill’s embedding database alongside the rest of our documentation.

This is a great way of addressing any shortcomings in your chatbot, but you need to be careful here. Unless you’re publishing these FAQs in a visible spot somewhere where they’ll be reviewed with the same frequency as your documentation, there’s a good chance they’ll fall out of date as your product changes.
Security considerations
One thing that’s important to remember when building a chatbot is that you might potentially be sharing information with a number of different third party services — not just OpenAI, but also the database that’s hosting your embeddings. And if you’re going with a third party solution, you have all of their infrastructure to be worried about as well! So you’ll want to do your due diligence there around these companies and their privacy and security practices.
Along those lines, you should always assume that your user will be able to get to any of this information — meaning your prompt text and the embeddings text — verbatim. A well-determined hacker could make this happen, but sometimes Bill volunteers that information himself.

That last line is an instruction we gave to Bill so he wouldn't use deprecated code samples
Obviously, for Bill this isn’t much of a problem. All of the information it uses consists of public documentation.
But think about support ticket threads, or those internal FAQs your customer support team might have, with comments like, “This is a bug — Tom said he’d have this fixed by Q2 but don’t give the customer any hard dates — we all know how optimistic Tom can be.” Is that something you’d want shared with your customer verbatim? Maybe not.
I think looking forward, this is going to be a challenge if we want Bill to be smarter around providing more personalized support. (Like having our customer’s support history included as part of our embeddings.) We’d need to make sure that data is strictly partitioned per customer, and there’s a lot more due diligence that would need to be performed around sending data to third-party resources. Plaid has whole teams dedicated to that, so I’ll let them worry about it. But that’s also a good reason to consider using alternatives that can be run entirely within your infrastructure.
The hardest part: Naming
We originally named our chatbot Finn (I liked to say his last name was “Teque”). And we all grew attached to that name. So you can imagine my shock when, heading back into San Francisco one night, I saw this billboard on the highway:

Yes, another company made a customer service chatbot and named it Fin. No, it has nothing to do with ours. Seriously, what are the odds?
So we bandied about a few names, a lot of which had some kind of finance pun attached to them. (Penny, Buck, Ira) We knew that our mascot was going to be a robot platypus * Plaid's always has a thing for platypuses , so we also looked at a few Australian-themed names, like Sydney and Mel. In the end, we decided on Bill because it happened to both a finance and platypus related name * Also, both are situations where a nest egg is important .
Looking back and looking ahead
Even now that I kinda understand how some of Bill works underneath the hood, I’m still really impressed by what it’s able to do. Sometimes it’s hard to hard to remember that it’s just “super-duper-fancy-autocomplete” underneath the hood, and I get offended on his behalf when people are rude with their questions. (Seriously; would it kill you to say “Please”?)
At the same time, I’m slightly less impressed with all these other products that are “Harnessing the Power of AI” to do some task, since I know that for half of these use cases, it really just means “We’re making an API call on the backend”
Looking forward, I think there’s a lot of fun experiments that we could try with Bill, and if any of them end up successful, I’ll post some updates! It’s also possible that by the time you read this, Bill will be replaced with an entirely different third party solution. If that’s the case, I like to imagine that Bill is happily retired, spending his days hanging out on a beach in Sydney, and still giving engineers relationship advice on his free time.
In the meantime, I’d love to hear from other people who tried — successfully or not — to build their own chatbots. Were you able to get something working? Any stories of your own you want to share, or advice you wish you had known at the beginning? Let me know in the comments below!