Playing Around with OpenAI's new Assistants API
So there was a lot of interesting news that came out of OpenAI’s Developer Day, but as somebody who’s recently spent a bunch of time building an AI-powered chatbot trained on our docs, I was very interested in their new Assistants API.
Recently at Plaid I created Bill — Bill is a chatbot that’s designed to answer questions about our developer documentation. And while my earlier blog post goes into much more detail around how it works, the general strategy that we used to build Bill went a little something like this:
- Through a series of Python scripts, I gathered content from our documentation, YouTube tutorials, implementation guides, and other assorted public documents, and chopped them up into chunks of text about 400 words long.
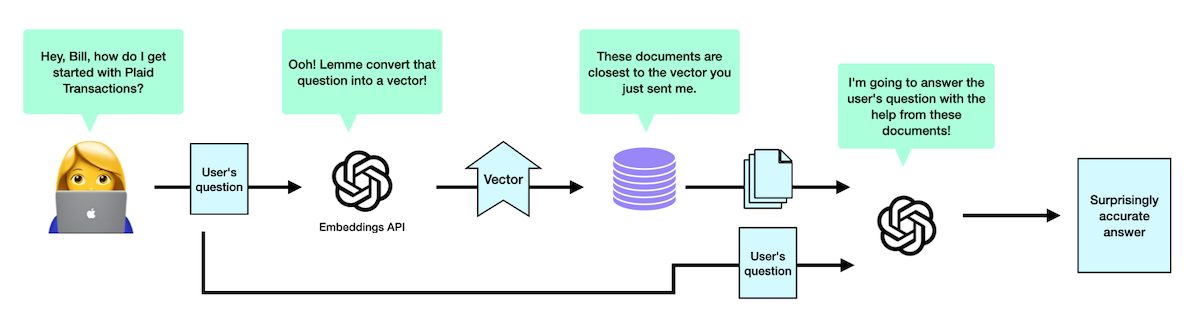
- Then, using the Embeddings API (a service provided by OpenAI), I’d get back a vector that describes how you would represent the meaning of this text as a point in space. I’d save this vector, alongside the rest of the text, in a database.
- When we receive a question, I use the same Embeddings API to generate a vector that represents that user’s question.
- We ask the database to find other vectors that are close to the user’s question, and return the chunks of text associated with those entries. These documents are the ones most likely to be relevant to our user’s original question.
- We then send the user’s question alongside those chunks of text to GPT-4, and it comes back with a surprisingly accurate answer.
- I also spent some time implementing “follow-up conversation” mode, where if a user asks a follow-up question, I sent the chat history over to GPT and use that to help figure out what question the user is really asking.
And so far, it’s been working out pretty well! We’re still adding tweaks here and there to get even better results, but generally speaking, we’ve gotten a lot of nice feedback, and have come to the conclusion that’s he’s generally made the developer experience better.
But building this chatbot was also a decent chunk of work; enough so that there’s been a number of third party solutions out there that will do all this work for you. And now, it looks like OpenAI is putting its own solution out there, too.
So, how do the new Assistants work?
The new Assistants works fairly similar to the way Bill works, but with OpenAI taking care of several of the steps that I had to build myself.
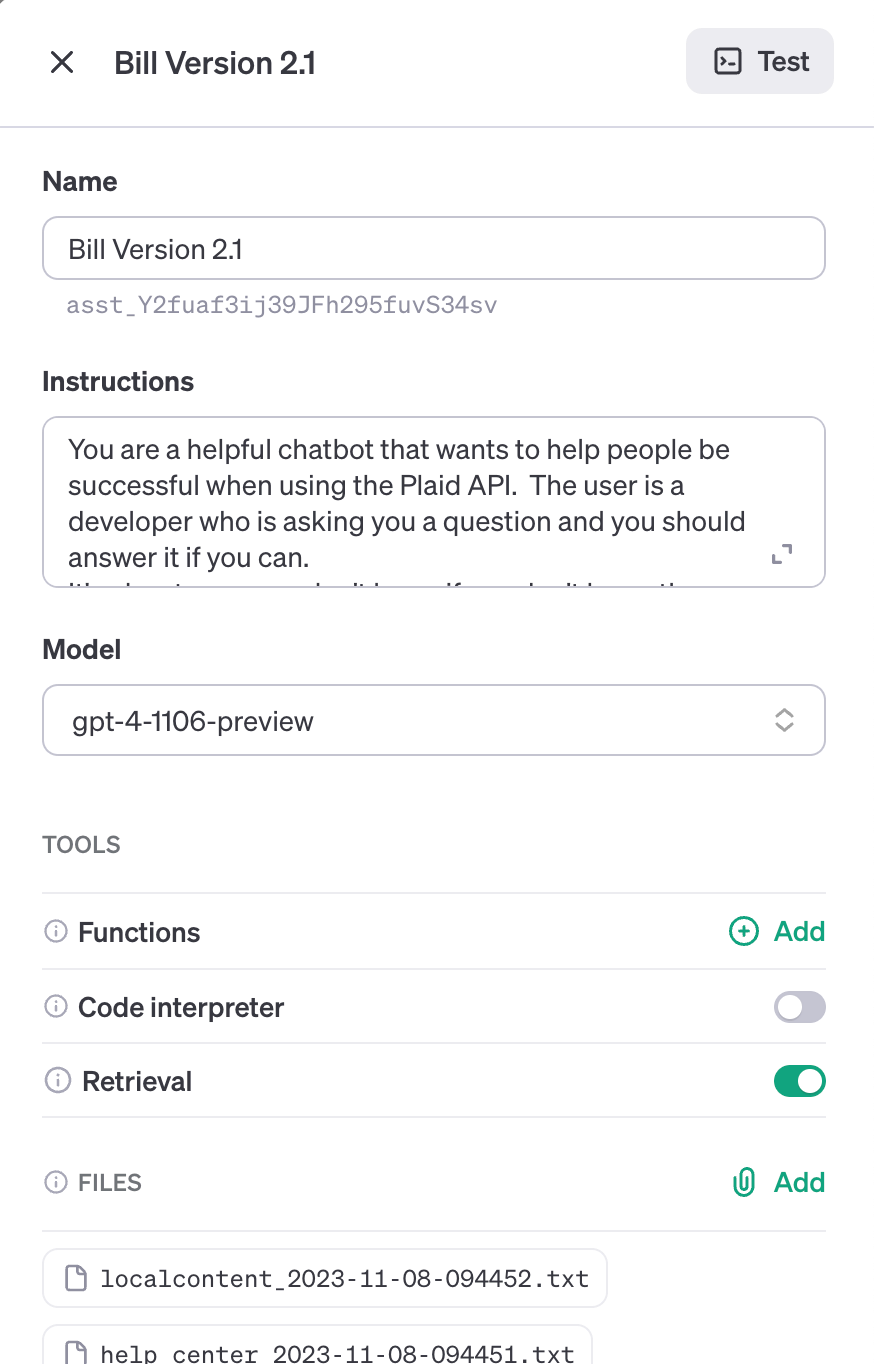
Basically, through OpenAI’s developer dashboard, you can ask to create a new Assistant — here, you can give it a custom prompt, tell it what LLM model it should be using, and enable three different tools:
-
Functions Is a really neat tool that I haven’t used much yet. Basically, if you have some custom functions available, you can tell the Assistant about them. The Assistant will then decide, based on the user’s question, if the best way to answer the user’s question would be by calling one of these functions.
I could see this being really useful in the future as a way to provide more customized customer support by searching through their logs, or checking the status of various banks, but we currently don’t make use of this.
-
Code Interpreter Allows the Assistant to write and run small bits of Python code if it decides that’s the best way to solve a problem. Here, I have an Assistant that’s using the code interpreter to find all of the 5 digit prime numbers that are also palindromes.

- Retrieval Allows the Assistant to supplement its knowledge with a number of different files (up to 20, each up to 512MB large) that you can upload. The Assistant automatically decides whether or not to take content from those files and use those to help solve the user’s questions.
So what’s really interesting here is that Retrieval is basically replacing steps 1-5 above with a simple interface where you flip a switch that says, “Yes, I’d like to use retrieval”. OpenAI’s documentation suggests that behind the scenes, it’s doing something similar to our process, where it’s breaking large content up into chunks and deciding which chunks to use based on their embedding vector.
It looked easy enough that I thought it would be worth building my own Assistant, and seeing how it compares to Bill; both from a bot creation standpoint, and from a quality standpoint.
Building the Assistant
So it turns out that re-creating Bill using the Assistant API and the dashboard was pretty straightforward. I got something simple working in an hour, and creating a full blown Assistant-powered backend took only a day or two.
First, creating the Assistant was pretty easy. I copied-and-pasted the same prompt I used for Bill, and flipped a few switches.
To create the giant files of content, I slightly modified the scripts I used to populate our vector database. I still grab content from all the same places as before, but instead of chopping it up into chunks and storing those chunks in a database, I’m appending these documents together into a small number of large files. Then (at least for now) I’m manually uploading those files in the OpenAI dashboard.
And, that’s all you have to do! Now, to be fair, I was able to reuse a good chunk of my code for grabbing content from our public docs, but all-in-all, if you’ve got a utility like Beautiful Soup (or LangChain), you can put your own Assistant together remarkably easily.
So I had an Assistant up and running, and I could talk to it from the dashboard. The next step was setting it up so that my server could talk to it.
Talking to the Assistant
Talking to the Assistant was also fairly straightforward, although the process works a little differently than what you might be used to if you’ve worked with OpenAI (or LangChain) in the past.
The biggest change is that OpenAI will manage the conversation history for you. This required a decent chunk of work with Bill, where we had to send down the user’s conversation history with every question they asked, then had GPT rephrase our user’s last question into something that works as a standalone question.
With Assistants, you don’t really need to do any of that. Instead, you simply create a “Thread” every time a user wants to start up a conversation. When your user asks a follow-up question, you add that message to the thread, and OpenAI figures out what the user’s follow-up question is asking based on the chat history.
Once you add a message, you then create a “run” object, where you pass in the thread. This run object corresponds to a process that is running on OpenAI’s backend and includes, among other thing, an ID.

At that point, you basically just periodically ping OpenAI for the status of that run.id, until it tells you that the run has completed. Once it’s been completed, you can then re-fetch the original thread, and there will be a new message added on to the thread that contains the Assistant’s response.
There's more code than this; it's not an infinite loop -- promise!
So in summary, the process looks a little something like this:
- Create a new thread
- Create a new message and add that to the thread
- Tell the thread to start running
- Monitor the “run” — basically, ask OpenAI for the status of the run and if it’s either queued or in progress, wait a little bit and try again.
- Once the run is complete, grab the newest message from the thread, and that’s the response from the Assistant.
So… how’d it go?
The reason I did all of this was to find out: Did the Assistant come up with answers that were any good? And I have to say, the results were… surprisingly disappointing! Often times, it would come up with answers that were very terse, and those terse answers often missed some important nuance that the old chatbot would usually include. Not only that, but the Assistant got answers wrong more often.
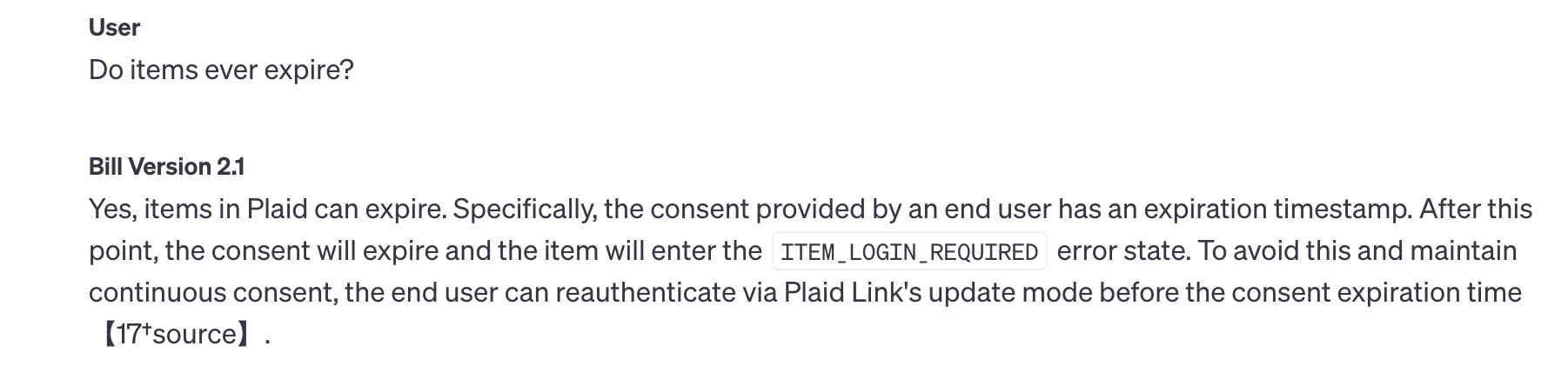
Not only is this answer overly-concise, it's also plain wrong.
Now, if you want hard numbers, I ran my admittedly-crude-but-still-helpful scoring test against the Assistant. This is a series of tests where I’d ask the system questions, get back answers, then ask GPT to grade these answers compared to an ideal answer with a set of scoring mechanisms.
Because I didn’t want to conflate the fact that the Assistant was using gpt-4-turbo (the “latest and greatest but still beta at the time of this writing” model), I also ran a series of tests against Bill — my old AI chatbot — using the new gpt-4-turbo model.
Now, again, you need to take these scores with a large grain of salt, but these were the results of my most recent run:
- Bill using gpt-4 (the original baseline): 70 / 100
- Bill using gpt-4-turbo: 80 /100
- The Assistant API: 46 / 100
What’s even more interesting is that if I just head on over to regular ol’ ChatGPT (with my premium account, using gpt-4) now that its dataset has been updated to April 2023, it does a better job of answering most * Obviously, it had the hardest time with questions about recent product releases. of these questions than the Assistant!
- Just asking ChatGPT Premium: 58/100
Now, I suspect that at least some of this is user error. Probably my prompt needs a little work — maybe what works well for a chatbot doesn’t work as well for an Assistant. Or maybe there are smarter ways for me to download or break up the supplemental text. Or maybe I’m missing some important step when calling the API.
But I suppose there’s also a chance that there’s some issues with the Assistant itself — after all, it’s still a beta product and it probably has a few kinks to work out. Now that it seems like the OpenAI drama has subsided, I’m hoping we’ll see a few improvements on this front.
A few other pros and cons
So on the bright side, being able to create an Assistant was really darned easy. Granted, a lot of that is because the parts that would have been difficult — fetching all of the content from our documentation, grabbing YouTube transcripts, etc. — was work I had done earlier. I just had to modify the scripts to save that text into files instead of chopping them up and adding them to a vector database.
In terms of drawbacks, two of the largest right now are:
- You can’t stream answers from the Assistant. It sounds like they’re working on adding this capability in the future, but it’s not a great user experience having nothing happen for several seconds while you’re waiting to get your complete answer back. (The bright side is that, because I’m using the Assistant with gpt-4-turbo, the amount of waiting is significantly reduced.)
- You’re no longer able to point to the original URLs that the material came from. With the old system, I was able to store the original URL alongside the chunk of content in my vector database. What this meant is that when a user asked a question, we could not only provide them with an answer, we could also provide them with good links to other resources that might solve their problem.
With the Assistant, we can’t really do that. It theoretically provides a list of sources (although at the time of this writing, there seems to be a bug where this list is empty), but those sources are just going to point to the uploaded files that I uploaded manually, and the user won’t be able to visit those.
Bill is safe for now
So, at this point, I don’t think I’m going to be swapping out our bespoke chatbot for an Assistant. But they do occupy an interesting middle ground between the no-code chatbots offered by paid third party solutions * Who, to be fair, are providing additional value on top of just having a chatbot. and building your own from scratch. At the very least, I think it’s worth playing around with, because I’m sure they’re only going to get better over time.
If you end up building one yourself, and have some good tips or tricks you feel like sharing, let me know!